/*
* @Author: cos
* @Date: 2022-04-05 00:10:59
* @LastEditTime: 2022-04-08 02:37:49
* @LastEditors: cos
* @Description: 词法分析器设计实现
* @FilePath: \CS\experiment_1\demo\main.cpp
*/
#include <iostream>
#include <vector>
#include <string>
#include <fstream>
#include <map>
using namespace std;
const string CategoryFileName = "./categoryCode.txt";
const string CodeFileName = "./code.txt";
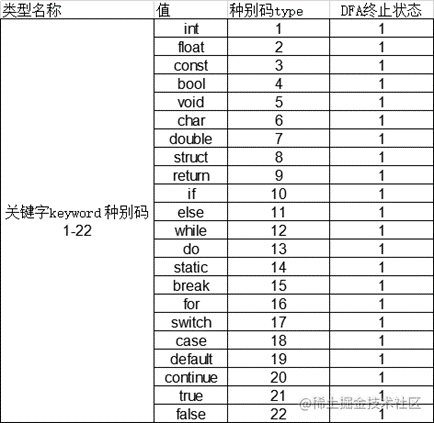
string keywords[22]; // 关键字表 种别码1-22
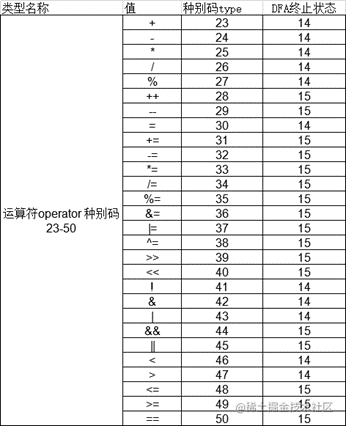
string operate[28]; // 运算符表 种别码23-50
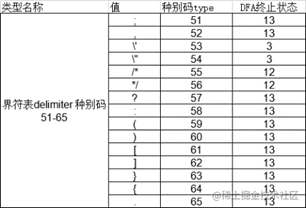
string delimiter[15]; // 界符表 种别码51-65
map<string, int> categoryCode; // 种别码表
const string op = "+-*/%=!&|<>";
const int _EOF_ = -2;
const int _ERROR_ = -1;
enum {
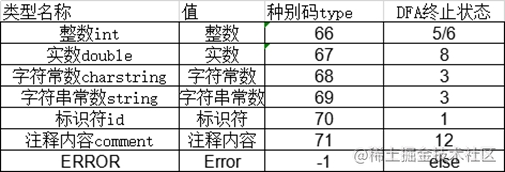
_ID_, _INT_, _DOUBLE_, _OPERATOR_, _DELIMITER_, _KEYWORD_, _CHAR_, _STRING_, _COMMENT_, _SPACE_
}; // 类型
string cat[10] = { "id", "int", "double", "operator", "delimiter", "keyword", "char", "string", "comment", "space" };
struct Token {
int type; // 种别码
string value; // 值 关键字/变量名/数字/运算符/界符
string category; // 种别码对应的类型名称
Token(int type, string value, string category) : type(type), value(value), category(category) {}
friend ostream& operator<<(ostream& os, const Token& t) {
os << t.category << ", type: " << t.type << ", value: " << t.value;
return os;
}
};
int pos, len; // 当前字符位置和长度
string code, tempToken; // 当前识别的字符串
vector<Token> tokenList; // 存储识别出的token
// 读文件
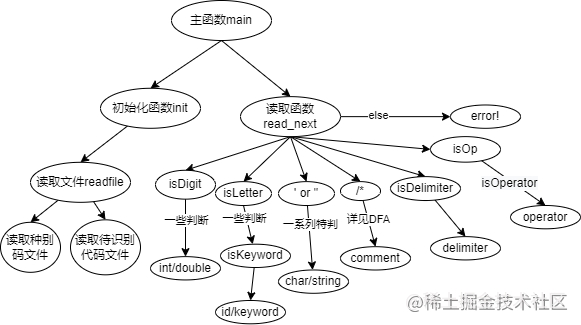
vector<string> readFile(string fileName) {
vector<string> res;
try {
ifstream fin;
fin.open(fileName);
string temp;
while (getline(fin, temp))
res.push_back(temp);
return res;
} catch(const exception& e) {
cerr << e.what() << '\n';
return res;
}
}
void init() {
vector<string> res = readFile(CategoryFileName);
// cout << "len:" << len << endl;
for(int i = 0; i < 22; ++i) {
keywords[i] = res[i];
categoryCode[res[i]] = i+1;
// cout << "keyword:" << res[i] << endl;
}
for(int i = 0; i < 28; ++i) {
operate[i] = res[i + 22];
categoryCode[res[i+22]] = i+23;
// cout << "operate:" << res[i + 22] << endl;
}
for(int i = 0; i < 15; ++i) {
delimiter[i] = res[i + 50];
categoryCode[res[i+50]] = i+51;
// cout << "delimiter:" << res[i + 50] << endl;
}
res = readFile(CodeFileName);
for(int i = 0; i < res.size(); ++i)
code += res[i]+'\n';
len = code.size();
}
char peek() {
if (pos+1 < len) return code[pos+1];
else return '\0';
}
inline bool isDigit(char c) {
return c >= '0' && c <= '9';
}
// 是否为字母或下划线
inline bool isLetter(char c) {
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_';
}
bool isKeyword(string s) {
for(int i = 0; i < 22; ++i)
if (s == keywords[i])
return true;
return false;
}
bool isOP(char ch) {
return op.find(ch) != string::npos;
}
bool isOperator(string s) {
for(int i = 0; i < 28; ++i)
if (s == operate[i]) return true;
return false;
}
bool isDelimiter(char ch) {
for(int i = 0; i < 15; ++i)
if (ch == delimiter[i][0]) return true;
return false;
}
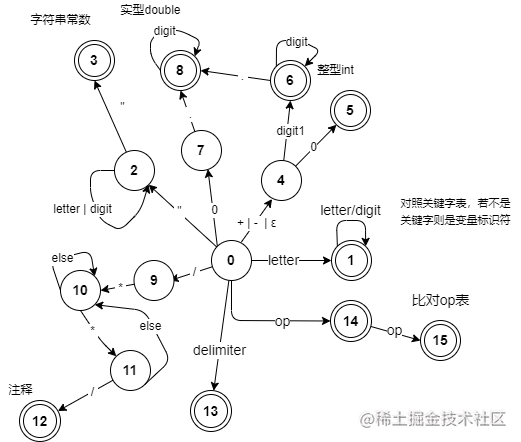
int judge(char ch) {
if(ch == '\n' || ch == ' ') return _SPACE_;
if(isDigit(ch)) {
char nextChar = peek();
if(ch == '0' && nextChar == '.') { // 0.多少
++pos;
if(!isDigit(peek())) // .后面不是数字
return _ERROR_;
tempToken = "0.";
while(isDigit(peek())) {
tempToken += peek();
++pos;
}
return _DOUBLE_; // 8
} else if(ch == '0' && !isDigit(nextChar)) { // 不是数字也不是.,说明是单纯的一个0
tempToken = "0";
return _INT_; // 5
} else if(ch != '0') { // digit1
tempToken = ch;
while(isDigit(peek())) {
tempToken += peek();
++pos;
}
char nextChar = peek();
if(nextChar == '.') {
tempToken += nextChar;
++pos;
nextChar = peek();
if(isDigit(nextChar)) {
tempToken += peek();
++pos;
while(isDigit(peek())) {
tempToken += peek();
++pos;
}
return _DOUBLE_; // 8
} else return _ERROR_;
} else return _INT_; // 6
} else { // 0+数字
++pos;
return _ERROR_; // ERROR
}
}
if(isLetter(ch)) {
tempToken = ch;
char nextChar = peek();
while( isLetter(nextChar) || isDigit(nextChar) ) { // 标识符~
tempToken += nextChar;
++pos;
nextChar = peek();
}
return isKeyword(tempToken) ? _KEYWORD_ : _ID_;
}
if(ch == '\"') {
tokenList.push_back(Token(54, "\"", cat[_DELIMITER_]));
tempToken = "";
char nextChar = peek();
while(nextChar != '\"') {
tempToken += nextChar;
++pos;
nextChar = peek();
}
tokenList.push_back(Token(69, tempToken, cat[_STRING_]));
tokenList.push_back(Token(54, "\"", cat[_DELIMITER_]));
pos += 2;
return _STRING_;
}
if(ch == '\'') {
tempToken = "";
++pos;
char nextChar = peek();
if(nextChar == '\'') {
tokenList.push_back(Token(53, "\'", cat[_DELIMITER_]));
tempToken += code[pos];
tokenList.push_back(Token(68, tempToken, cat[_CHAR_]));
tokenList.push_back(Token(53, "\'", cat[_DELIMITER_]));
++pos;
return _CHAR_;
} else if(code[pos] == '\'') {
tokenList.push_back(Token(53, "\'", cat[_DELIMITER_]));
tokenList.push_back(Token(68, tempToken, cat[_CHAR_])); // 空字符串
tokenList.push_back(Token(53, "\'", cat[_DELIMITER_]));
return _CHAR_;
} else {
while(pos < len && nextChar != '\'') {
++pos;
nextChar = peek();
}
++pos;
return _ERROR_;
}
}
if(ch == '/') {
if(peek() == '*') {
++pos;
char nextChar = peek();
++pos;
tempToken = "";
while(pos < len) {
if(nextChar == '*' && peek() == '/') {
tokenList.push_back(Token(55, "/*", cat[_DELIMITER_]));
tokenList.push_back(Token(71, tempToken, cat[_COMMENT_]));
tokenList.push_back(Token(56, "*/", cat[_DELIMITER_]));
++pos;
++pos;
return _COMMENT_;
} else {
tempToken += nextChar;
nextChar = peek();
++pos;
}
}
return _ERROR_;
}
}
if(isOP(ch)) { // op运算符
tempToken = "";
tempToken += ch;
char nextChar = peek();
if(isOP(nextChar)) {
if(isOperator(tempToken + nextChar)) {
tempToken += nextChar;
++pos;
return _OPERATOR_; // 15
} else return _OPERATOR_; // 14
} else return _OPERATOR_; // 14
}
if(isDelimiter(ch)) {
tempToken = "";
tempToken += ch;
return _DELIMITER_;
}
return _ERROR_;
}
int read_next() {
int type = judge(code[pos]);
while(pos < len && type == _SPACE_) {
++pos;
type = judge(code[pos]);
}
if(pos >= len) return _EOF_;
++pos;
if(type == _ERROR_) return _ERROR_;
if(type == _DOUBLE_) {
// cout << "double: " << tempToken << endl;
tokenList.push_back(Token(67, tempToken, cat[_DOUBLE_]));
return _DOUBLE_;
}
if(type == _INT_) {
// cout << "int: " << tempToken << endl;
tokenList.push_back(Token(66, tempToken, cat[_INT_]));
return _INT_;
}
if(type == _ID_) { // 标识符
// cout << "id: " << tempToken << endl;
tokenList.push_back(Token(70, tempToken, cat[_ID_]));
return _ID_;
}
if(type == _OPERATOR_ || type == _KEYWORD_ || type == _DELIMITER_) {
tokenList.push_back(Token(categoryCode[tempToken], tempToken, cat[type]));
return type;
}
return _ERROR_;
}
int main() {
init();
while(pos < len) {
int flag = read_next();
if(flag == _EOF_) break;
else if(flag == _ERROR_) tokenList.push_back(Token(_ERROR_, "ERROR!", "ERROR"));
}
for(auto t : tokenList)
cout << t << endl;
return 0;
}